
他的跳棋程序是人工智能的第一次展示
在1956年人工智能的第一次头脑风暴会议上,除了来自大学及贝尔实验室的数学家和研究人员之外,还有几位IBM的工程师和科学家。例如:纳撒尼尔·罗切斯特(Nathaniel Rochester)和亚瑟·塞谬尔(Arthur Samuel)等。罗切斯特是IBM的信息研究主管,当年达特茅斯会议发起人之一,他领导IBM的一个小组,开创了实现AI领域突破的IBM传统;而塞缪尔,则是其小组中作出重大成果的第一位成员。塞缪尔在他独立研发的西洋跳棋计算机程序中,首次提出并实现了如今AI的核心技术之一:“机器学习”(Machine Learning)的概念。
电脑游戏和AI
人工智能的发展历程中,计算机游戏的研究一直是个亮点。特别是作为游戏中智能之最的象棋和围棋,被公众喜爱,也激发科学家们的研究兴趣。许多数学家和计算机学者,包括图灵、香农、麦卡锡等,都写过下象棋的程序。此外,许多小游戏,诸如井字棋、五子棋、跳棋等,规则更简单但输赢标准明确,也需要一些细微的考虑和复杂的决策,并且很方便测试机器的计算能力及智能程度,容易将其与人类的性能进行比较。因此,就如同生物学研究中的果蝇和小白鼠一样,游戏成为AI研究者们的好帮手。
在棋类游戏的计算机程序研发史上,IBM的功劳不小。这个运转了100多年的“商业机器公司”,不愧是一个伟大的企业。它不仅数次改变了世界商业的运行模式,也在科学技术领域扮演了一个不平凡的角色。可以说,它直接促成了微软、英特尔等新巨头的诞生,引领了计算机科学和人工智能发展的方方面面。一百多年过去了,科学技术领域发生了翻天覆地的变化,为了应对科技的发展,IBM不断地实验,不停地创新,这正是它能多次转型,将生命力延续百年而屹立不倒的秘诀之一。

图1:参加达特茅斯AI会议的几位IBM科学家
IBM的研究人员,开发过多种电脑游戏软件。从今天我们要介绍的塞缪尔的跳棋[1]开始,紧接着还有一位亚历克斯·伯恩斯坦(Alex Bernstein),是数学家和经验丰富的国际象棋棋手。伯恩斯坦也被邀参加了达特茅斯会议,他在会上受到麦卡锡的启发,之后他领导几位同事一起探索象棋程序,并最终于1957年在IBM 701上完成,这是历史上第一个完整的国际象棋程序。再后来,IBM又有了TD-Gammon 西洋双陆棋程序,它和塞缪尔的跳棋程序一样,两者都使用了让机器通过反复试验来提高游戏水平,与人类思维非常相似的学习方式,是现代机器学习技术的最早范例。
最终,在这些成就的基础上,IBM 研究人员开发出了足够复杂、能与人类专家竞争的神经网络,研发了深蓝(Deep Blue)的国际象棋程序,于 1997 年成为第一台击败国际象棋世界冠军加里·卡斯帕罗夫的机器。
在IBM这些成果的推动下,若干公司及众多学者的努力下,将近20年后的2016年,谷歌又进一步推出了AlphaGo,挑战并打败了人类的顶级围棋大师李世石,并以4:1的比分得胜。之后,升级的阿尔法狗又以“Master”的网名约战中日韩围棋大师,并取得60局连胜。这些计算机弈棋的不断进步,将机器学习、神经网络、深度学习,蒙特卡洛搜索等多种方法集合在一起,大大推动了AI进步,最终让它发展到今天“百花齐放”的状态。人工智能,已经深入到了普通人的生活中。
回溯历史,电脑游戏的研究,伴随着AI的进步。弈棋研究中的突破,也相应在AI历史上竖起了一个一个的里程碑。这第一个里程碑。便是70多年前塞缪尔开发的西洋跳棋程序。
塞缪尔和电脑跳棋
亚瑟·塞谬尔(Arthur Samuel,1901—1990)生于美国堪萨斯州,他于1926年在麻省理工学院得到电机硕士的学位,然后担任了两年的教员后,进入贝尔实验室从事真空管的研究,改进雷达等工作。二战时期,他开发了一个气体放电开关,使得一个天线能同时用于发送与接收讯息。塞谬尔于战争结束后,进入伊利诺伊大学香槟分校,参与开始建构ILLIAC电脑的计划,但电脑完成前他就离开了。然后,他在1949年来到了IBM位于纽约州的实验室。
塞谬尔最成功的成就大多是在IBM开始和进行的。他影响了IBM对晶体管计算机的早期研究,他参与了IBM 第一台存储程序计算机 701 的开发工作。该计算机的内存基于威廉姆斯管,该管将位元存储为阴极射线管屏幕上的带电点。塞谬尔设法将存储的位数从通常的 512 个增加到 2048 个,并将平均无故障时间提高到了半小时。
早在1949年,塞谬尔就有了开发跳棋程序的设想,为什么选择跳棋而不是国际象棋呢?因为跳棋相对简单,但在策略上又有一定的深度,可以对人工智能和机器学习进行富有成效的研究。他于 1952 年首次为 IBM 701 编写跳棋程序,并且于 1955 年完成了具有良好棋艺技巧的第一个程序。

图2:电视节目中,塞缪尔在IBM 701上向公众展示计算机“跳棋”
1956年2月24日,塞缪尔的“跳棋”节目在IBM 701上运行,在电视上向公众展示和播放。这程式因为表明了当年电脑硬件的进步和作者的程式编写技巧而轰动一时。当该程序即将演示之前,IBM 创始人兼总裁老沃森高兴地预测,这个电视播放将使 IBM 股票价格上涨 15 点!之后的效果果然印证了沃森这句话。除此之外的另一个收获是,这个电视节目使公众第一次认识到,电脑不仅可以用作复杂的数学计算,也能用于带娱乐性质的游戏。这被公认为是人工智能的首次展示,这个程序也被认为能够“学习”,让人们首次了解到:计算机的确可以具有“智能”!
塞缪尔的“跳棋”节目电视播放几个月后,正值达特茅斯研讨会召开,多位与会者都热衷于研究计算机弈棋技巧,成为讨论的热门话题。
1966年,塞谬尔自IBM退休并成为斯坦福大学教授,之后他在斯坦福担任教职直至1990年因帕金森氏症并发症而去世。在斯坦福时他继续研究西洋跳棋,直到70 年代时他的跳棋程序被更先进的方法所替代。他也与著名的计算机专家高德纳发展TeX计划,并为之撰写了文件,据说他在88岁生日后依旧撰写程式。
塞谬尔是一位谦虚低调、埋头苦干的学者,客观务实且乐于助人,特别是在他了解并擅长的许多领域,尽其所能地帮助其他人。
下面,我们简要解释一下塞谬尔在跳棋程序中采用的Minimax算法,以及如何让机器自我学习,真实地体会一下AI中的电脑弈棋是如何工作的。
极小极大(Minimax)算法
塞谬尔思考,如何设计一个复杂的程序来下跳棋?他记起香农曾经写过关于用机器下国际象棋的文章[2],猜想香农知道如何构建程序。1949 年,当塞缪尔前往芝加哥去见香农时,才知道具体程序实际上还没有被创建出来,香农只是笼统地泛泛而谈,并没有真正涉及到计算机。因此,塞谬尔决定动手编写一个能够展现这一普遍问题的机器下棋智能程序,因为它可以提供解决此类战略问题的一般结构。
香农提出的基础算法今天被称为Minimax(极小极大算法),以冯·诺伊曼提出并证明了的极小极大值定理命名。这个方法适合于两个玩家对弈的游戏。为了方便解释,我们且将他们称为“玩家”和“对手”。“极小极大”的意思是说,游戏玩家应该如此行动,以尽量“减小”(极小化)可能的最坏情形下的“最大”损失。这儿所说的“极小“和”极大“,都是针对玩家而言的,而“对手”的策略,则与玩家的策略相反。
说得更为具体一点,假设玩家和 “对手”都会考虑整个游戏的未来状态,那么,你的每一步应该这样选择:即使对手也总能按照同样策略来选择他的最佳回应,但在比赛结束时你仍然可以获得你能得到的最好结果,或者说,将最大风险极小化。
计算机的原理是数值计算,因此,刚才叙述的“极小极大”思想需要量化。因为弈棋过程实际上就是棋盘上棋子分布状态一步一步改变的过程,所以,量化可以通过一个“状态S的价值函数F(S)”来达到。状态函数F(S)赋予每个状态一个数值,来评估不同状态对玩家的优劣,函数值大利于玩家。所以,在下面例子中说法反过来了:玩家的目标是最大化max获胜位置的价值,对手则要减小min状态函数值。
对计算机程序而言,游戏开始之前,起码需要做到两点:一是根据游戏规则,产生一个游戏的“路径树“,即根据游戏规则,从当前状态生成所有可能的下一个状态,以及这些状态的再下一个可能状态,等等。二是定义对玩家(这儿是计算机)有利的价值函数,即给路径树上每个状态赋值。
例如,考虑一个非常简单的“井字棋“游戏,规则是两方轮流、一次一步,首先将3个棋子连成一线(横竖斜)的一方为赢家。图3是简化了的井字棋的游戏路径树及状态函数值。
从图中可见,玩家(X)先走第一步,这时有9种可能的选择;对手第二步,8种选择;然后游戏继续直到结束。结束时的状态函数值(+1、0、-1)决定最后的输赢。
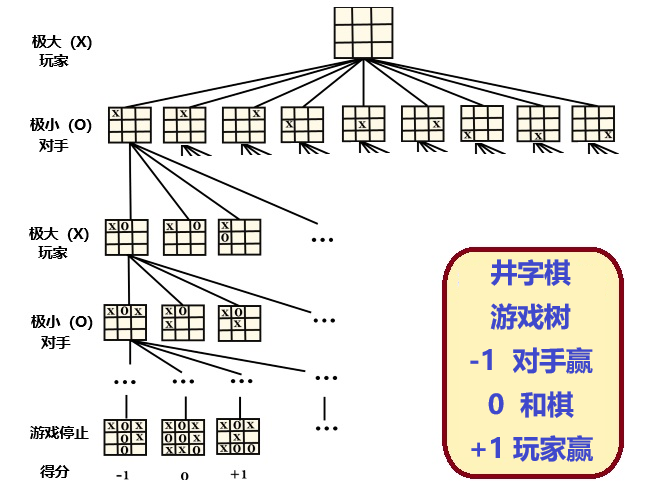
图3:井字棋的部分路径树和最后得分
按照刚才的说法,玩家得分越高赢的可能性越大,反之,“对手“分低为赢。因此,玩家根据评分函数走分数最高的棋步。机器的程序一旦确定了,便只按照最佳路径的动作来达到最佳游戏结局,并不在乎对手可能犯下的错误。
为了说明极小极大算法之原理,上述井字棋仍然太复杂,因此再举下面更简单的例子,见图4。
假设正在玩的游戏每步每一方最多只有两种可能的动作。该算法生成了图4的路径树,这儿只有4步游戏过程。你不用纠结于“这是什么游戏,游戏的规则如何,何种状态函数”等等问题,但我们知道它有如图所示的路径树,以及最下一排的状态,即最后一排蓝框里的圆圈中显示的数值。
当状态函数等于正无穷大“+∞”,玩家赢;函数等于负无穷大“-∞”,对手赢;因此玩家总是选择状态函数值最大,即max的路径;对手总是选择状态评价函数值最小,即min的路径。
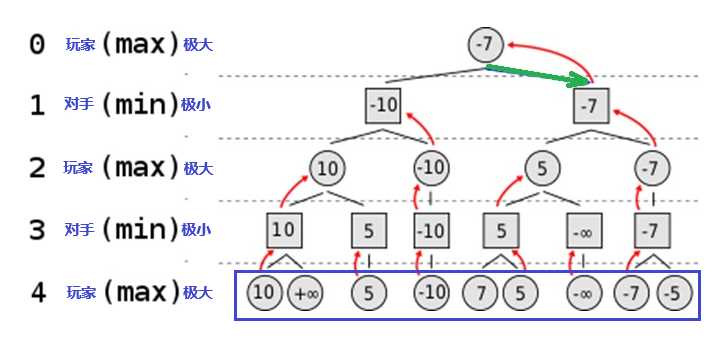
图4:极小极大法一例
根据上述原则,可以从路径树,以及最下一排的数值,倒推回去来决定玩家的第一步应该怎么走,才符合Minimax算法的要求,图4中,倒回去的步法用红箭头表示。
根据Minimax算法的原则,对该例所示的情形得到的结论是:玩家的第一步应该选择往右走一步,也就是图中绿色箭头所指的位置。这样选择后,每一步沿着红箭头的反方向朝下走,第四步得到的评价函数值等于-7。尽管不是“+∞”,但已经是该特定情况下玩家可能取得的最好结果。
机器学习
上面说到的状态评价函数F(S)很重要,它决定了计算机的下棋能力。如果用人来打比方的话,就好比是每一个奕棋者脑袋里都有一个他自己的F(S),从这个函数,他与人对弈时可以看到好几步后的情形,从而来选择当下更“好”的一步。
看到这儿,你可能会说:那好啊,让计算机模拟国际冠军脑袋中的评价函数不就行了吗?或者你会认为,下棋高手可以建造出更高明的走棋程序。
其实不然,产生上述想法的根源是因为忽视了“学习”。
人类具有学习的能力,这是显示智力的重要标志之一。那么,能否使机器也具有这种能力呢?为了达到这样的目的,塞缪尔引入了一种机制,让他的跳棋程序可以从已经玩过的游戏中学习。塞缪尔让计算机记录了它看到的每个位置以及该位置最终是否导致胜利或失败;将这些经验纳入其后续决策中,程序玩的游戏越多,效果就越好。塞缪尔将这一过程称为“机器学习”,他创造的这个术语至今仍然是人工智能的核心。1962 年,塞缪尔跳棋在与自己进行了数千场对弈以提高其技能后,击败了自称“跳棋大师”的罗伯特·尼利。随后,尽管它与人类对手的战绩参差不齐,但塞缪尔制定的原则为 20 世纪 90 年代 IBM 在人工智能方面的一系列突破奠定了基础。
人类下棋高手也是从下棋的经验中“学习”才取得成功的,机器的优势是在于它的速度和精确性,假设人类棋手一年下1,000 盘棋,而计算机几天或几小时就可以达到这个目标。因此,计算机的速度使它有可能在短期内被训练而达到专业棋手级的水平。
塞缪尔跳棋的关键之处就是在于它能“学习”,在它训练和学习的阶段,它可以不断地更新它的评价函数F(S)。塞缪尔为他的跳棋设计的学习方法,叫做“时间差分学习”方法。从今天机器学习的分类来看,是属于强化学习[3]。
现代机器学习大体分为3类:监督学习、无监督学习、强化学习,见图5。
监督学习是从有标记的训练数据中推导出预测函数,即给定数据,预测新数据。例子:孩子学认字,预测公司收益等。
无监督学习是从无标记的训练数据中推断结论,即在给定数据的引导下,寻找隐藏的结构。例子:孩子通过自己每天观察到的各种事物,自动将其分类和识别:动物、植物、鸟、房屋等等。
强化学习关注的是与环境的互动:采取行动,从环境得到反馈,然后逐步改进行动的策略。例子:学习下棋的过程。

图5:机器学习种类
跳棋程序在下棋的过程中,棋手走的每一步棋存在“好坏”之分,如果下得好,是一步好棋;下得不好,则是一步臭棋。评价函数给每一步行动后的状态赋值,相当于环境给出了一个明确的反馈,是好还是坏?“好坏”程度如何?然后,机器再根据反馈来更新它的评价函数。
塞缪尔的跳棋程序采用时间差分技术,通过自身的行动和奖励来进行学习。时间差分学习的关键见解是即使没有关于最终结果的知识,状态的价值可以根据后续状态的价值来进行更新。
培训过程中,该程序会从随机位置开始自我对战多局。每一步,程序都会选择能够最大化获胜机会的移动,根据当前状态价值函数进行决策。随着游戏的进行,该程序会使用一个公式来更新状态价值函数,该公式将当前状态的价值估计和下一个状态的价值估计结合起来。这个更新被称为时间差分,因为它测量了当前状态的价值估计和下一个状态的价值估计之间的差异。通过反复进行这个过程,并不断更新状态价值函数。通过反复进行这个过程,并不断更新状态价值函数,程序逐渐改善了其下棋能力。
塞缪尔的时间差分学习为强化学习领域带来了重要的突破,它的应用广泛,包括机器人技术、决策系统等各个领域。
塞缪尔的工作对现代机器学习产生了深远的影响。他的国际跳棋程序展示了机器能够通过迭代反馈和经验来学习并提高性能的潜力。他在自主学习、强化学习、特征提取和泛化等方面的贡献,影响了后续机器学习算法的发展。塞缪尔的研究激发了人们对机器学习的热情和探索,推动了神经网络、决策树、强化学习和其他机器学习技术的进步。
塞缪尔1952年首次开发的跳棋程序,被广泛认为是人工智能和机器学习领域的一项重大成就。
参考文献:
[1]维基百科(Arthur Samuel)
https://en.wikipedia.org/wiki/Arthur_Samuel_(computer_scientist)
[2]Claude Shannon (1950). "Programming a Computer for Playing Chess" (PDF). Philosophical Magazine. 41 (314).
[3]Samuel, A. L. (1959). Some studies in machine learning using the game of checkers. IBM Journal of research and development, 3(3), 210-229.
(本文首发于微信公众号“知识分子”)